机器学习模型两个主要的误差来源:偏差和方差
在构建模型时,设法降低这两个主要误差(可以用学习曲线),模型的准确度会更高。
偏差-方差权衡
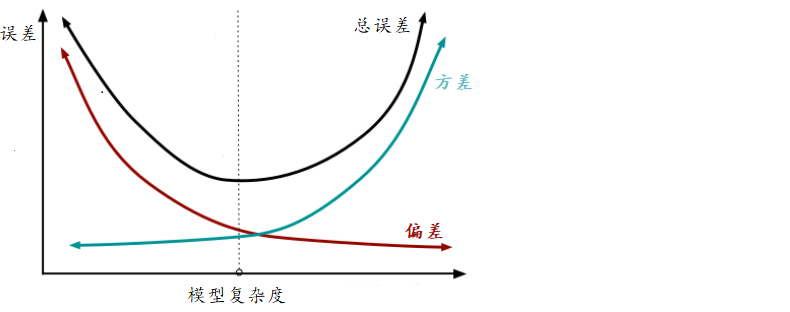
高偏差的模型方差小,低偏差的模型方差大,所以不能同时拥有较低的偏差和方差,需要在二者之间做一个权衡。
什么是偏差? 比如线性回归模型,它假设特征和目标之间存在线性关系,但是对于大多数实际场景来说,特征和目标之间的真实关系是复杂且非线性的。此时简化的假设,就会给模型带来偏差,对真实关系的假设错误越多,偏差越高,反之亦然。
什么是方差? 在监督学习中,假设特征和目标间存在某种关系,并用模型f来表示这种未知的关系。但在实际应用中,f几乎是完全未知的,所以我们试着用f(^)来预测,使用某一数据集会输出一个f(^),使用不同的数据集,也许会输出不同的f(^)(总结:随着训练集的改变,输出不同的g,变化的量叫做方差)
为什么高偏差的模型方差小? 如下图,当训练集发生改变时,线性回归模型f(^)没有太大变化,所以方差很小。同理:对于低偏差的模型,训练集改变时模型f(^)发生较大变化,方差较大。
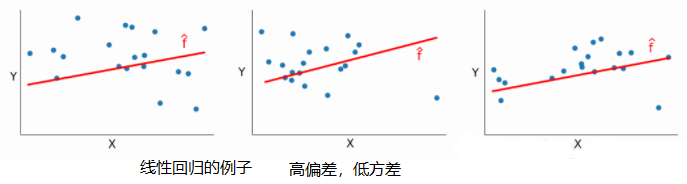
权衡偏差和方差 (如下图)一般来说,在某些测试数据上进行测试时,模型g会有一些误差。偏差和方差只会增加误差,我们希望偏差较低→以避免建立一个过于简单的模型(一个简单模型在训练集、测试集上的表现都很糟糕);同样我们也希望方差较低→以避免建立一个过于复杂的模型(一个复杂模型完全适合训练集上的所有数据点,但这只是更大样本集的一个小样本集、数据点包含的噪音也被模型捕捉到,所以在测试集上的表现通常很糟糕)
学习曲线
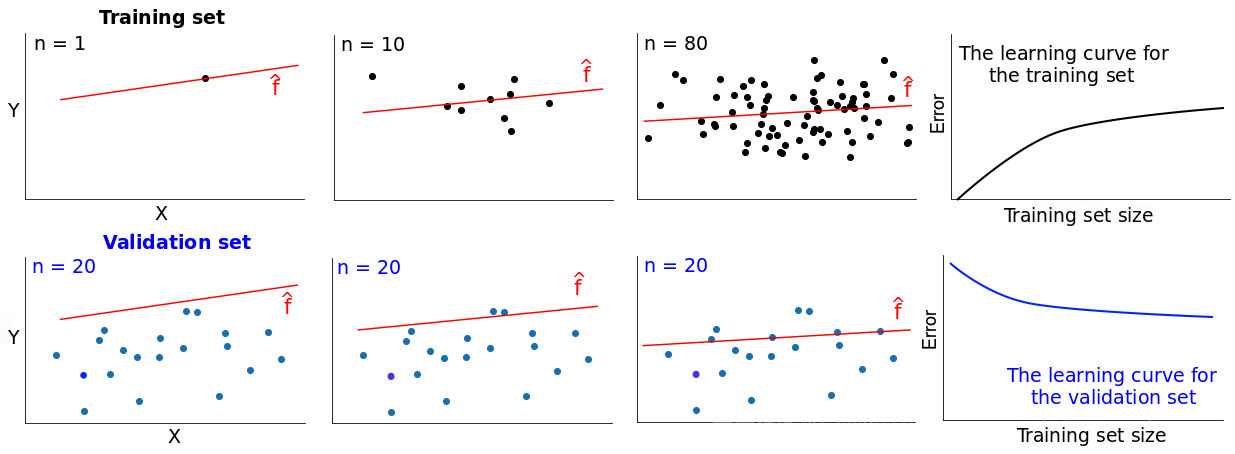
根据训练集大小的变化绘制训练误差和测试误差,得到两条曲线,这两条曲线被称为学习曲线。学习曲线展示了随着训练集数据量的增加,模型误差的变化。
N=1时(N为训练实例的数量),该模型完全适合单个训练数据点,误差为0,但并不适合于20个不同数据点的验证集,误差要高的多。随着N增大,模型不再适合训练集,训练误差变大。然而模型是在更多数据上训练的,因此可以更好的适应验证集,验证误差减少。
检测偏差和方差
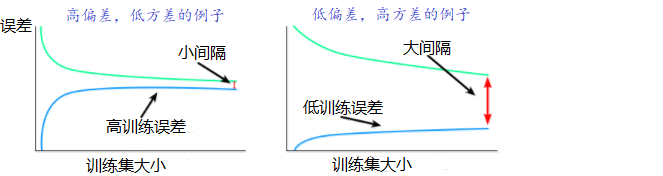
如何看偏差的高低? 看训练误差,训练误差很低→低偏差,训练误差很高→高偏差
如何看方差的高低? 看训练和验证训练学习曲线之间的间隔(间隔 = 验证误差 - 训练误差),误差差异越大,间隔就越大,方差就越大
补充:描述模型有多差的误差度量,不可约误差给出一个下限:不能低于该下限值。描述模型有多好的误差度量,不可约误差给出一个上限:不能超出该上限值。在很多技术著作中,贝叶斯误差率通常用来指代分类器的最佳误差值,类似于不可约误差。
应对策略
(1)高偏差、低方差的算法
它对训练数据欠拟合。此时增加训练数据的实例,也不可能会构建更好的模型。一般改进高偏差、低方差的方法如下:
①增加更多的特征
②调整模型参数,增加模型的复杂度
③降低正则化系数(正则化阻止了算法更好的拟合数据)
(2)低偏差、高方差的算法
它对训练数据过度拟合(模型在训练集上表现良好,在验证集上表现很差)。此时添加新的训练实例,很可能构建更好地模型,因为验证曲线在最大训练集上没有趋于平缓,所以因此仍有潜力收敛到训练曲线。一般改进低偏差、高方差的方法如下:
①减少当前训练数据特征数量,或降维
②调整模型参数,降低模型的复杂度
③增加更多的训练实例
④增加正则化系数
交叉验证
学习曲线上每一个横坐标的刻度,可以是一种数据集的分割方式。在每个刻度上应用k折交叉验证方法,会得到k个训练误差、k个验证误差,然后分别取平均值。最后每个刻度上就会有1个训练误差平均值、1个验证误差平均值,用它们绘制学习曲线。