1、逻辑回归模型
内容:①分类问题:什么问题才算是分类问题,为什么能用逻辑回归算法解决分类问题
②模型表示:将训练集输入到模型后,能得到在[0,1]区间内的值,这个值就是y为正向类的概率
③判定边界:用于理解逻辑回归的模型表示,即它是如何对数据进行分类的
④损失函数:要拟合逻辑回归模型的参数θ,应先定义用来拟合参数的优化目标(即损失函数)
⑤梯度下降,用梯度下降法求解使损失函数最小的参数
⑥多类别分类:通过“一对多”的分类算法,将逻辑回归算法应用到多类别分类问题上
分类问题
我们将学习逻辑回归算法,是目前最流行使用最广泛的用于解决分类问题的学习算法。在分类问题中,要预测的是离散值,即预测某一样本属于哪一类。比如判断一封电子邮件是否是垃圾邮件、判断一次金融交易是否是欺诈等。
从二分类问题开始讨论。二分类将输出类别分为正向类(用1表示)、负向类(用0表示),如何解决二分类问题?如果用线性回归算法来解决,当h>=0.5时y=1,h<0.5时y=0,但线性回归算法很容易受到离群点的影响,而且如果h远大于1或远小于0,会很奇怪,所以改用逻辑回归算法,因为它的输出值永远在0到1之间
模型表示
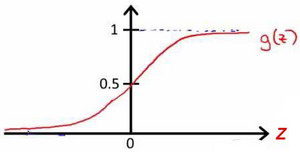
逻辑回归模型的假设是 $h_θ(x)=g(X\cdot θ)$,其中X是特征矩阵,g是逻辑函数,一个常用的逻辑函数是S型函数(Sigmoid函数),公式是$g(z)=\frac{1}{1+e^{-z}}$,它的值永远在0到1之间(如下图所示),相当于y=1的概率P(y=1|x;θ),比如对于给定的x,通过已经确定的参数计算出$h_θ(x)=0.7$,则表示有70%的几率y为正向类,有30%的几率y为负向类
判定边界
在逻辑回归中,我们预测:当h>=0.5时,y=1,当h<0.5时,y=0,根据s型函数图像,可以得到z>=0时,h>=0.5,z<0时,h<0.5,所以最终得到$θ^Tx≥0$时预测y为1,$θ^Tx<0$时预测y为0
比如我们的数据呈现以下两种分布,用什么模型才适合呢?
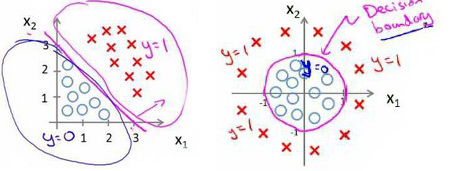
左图:可以用线性模型分割,$h_θ(x)=g(θ_0+θ_1x_1+θ_2x_2)$,$θ=(-3,1,1)^T$,则当$-3+x_1+x_2≥0$时模型将预测y=1,画出直线$x_1+x_2=3$就是模型的分界线,它将预测为1的区域和预测0的区域分割开
右图:需要用曲线才能分隔开,用二次方特征,$h_θ(x)=g(θ_0+θ_1x_1+θ_2x_2+θ_3x_1^2+θ_4x_2^2)$,$θ=(-1,0,0,1,1)^T$,得到的判定边界是以(0,0)为原点,半径为1的圆
损失函数
回顾线性回归模型:损失函数是误差的平方和。如果逻辑回归模型也用这个损失函数,将$h_θ(x)=\frac{1}{1+e^{-θ^Tx}}$代入后得到的损失函数是一个非凸函数,即损失函数有很多局部最小值。
重新定义逻辑回归的损失函数:,其中当实际y=1时Cost(h,y)=-ln(h),当实际y=0时Cost(h,y)=-ln(1-h)
简化后得:
代入损失函数得:
梯度下降
得到损失函数后,就能用梯度下降算法来求得能使损失函数最小的参数了,参数的更新公式是 ,推导过程如下:
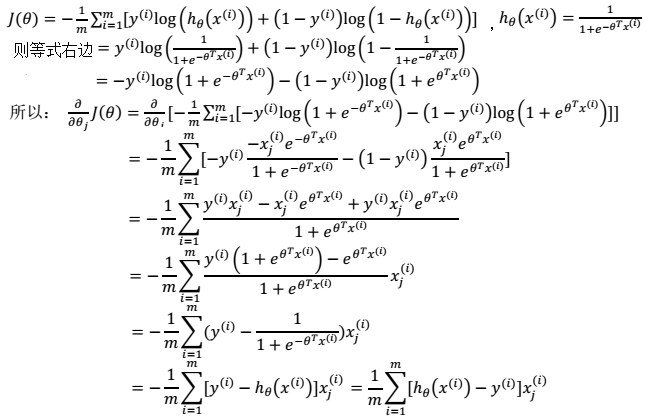
虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的$h_θ(x)=g(X\cdot θ)$与线性回归中的不同,所以实际上也是不一样的。
回顾线性回归的梯度下降法,①谈到了如何监控梯度下降法以确保其收敛,我通常也把同样的方法用在逻辑回归中,来监测梯度下降,以确保它正常收敛;②在运行梯度下降算法之前还需要进行特征缩放,能提高收敛速度;③用向量化的方式可以同时更新参数
其它常被用来令损失函数最小的算法(这些算法更加复杂和优越,不需要人工选择学习率α,比梯度下降算法更快):①共轭梯度 ②局部优化法 ③有限内存局部优化法(LBFGS)
多类别分类:一对多
多类别分类就是一个样本所属的类别不止有两种,比如将邮件归类到不同的文件夹里,或自动加标签,y可以取1,2,3,…对于从0开始还从1开始都不重要,怎么标都不会影响最后的结果。
如何进行一对多的分类工作?比如有3个类,①先从类1开始,将类1定为正类,将类2和类3定为负类,用逻辑回归算法得到模型1 ②再从类2开始,将类2定为正类,类1、3定为负类,用逻辑回归算法得到模型2 ③相同方法得到模型3 ④拿到一个新样本做预测时,将所有模型都运行一遍,选择输出值最大的那个模型对应的正类。
练习
2、正则化
内容:①过拟合问题:什么是过拟合问题、如何解决这个问题
②正则化:可以改善或者减少过度拟合问题
过拟合问题
到现在为止,我们已经学习了2种分类算法:线性回归、逻辑回归,它们能够有效地解决许多问题,但是将它们应用到某些特定的机器学习应用时,会遇到过拟合问题,可能会导致它们效果很差。
什么是过拟合问题?①如果我们有非常多的特征,通过学习得到的假设可能会非常好地适应训练集(损失函数几乎为0),却不能推广到新的数据;②模型越复杂(比如多项式x的次数越高),在训练集上拟合的越好,但对新数据的预测能力会变差
如何解决过拟合问题?①丢弃一些不能帮助我们正确预测的特征:可通过人工选择保留哪些特征,或者利用一些模型选择的算法(比如PCA);②正则化:保留所有的特征,但是减少参数的大小
正则化
对于多项式回归模型,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,就能很好的拟合了,这就是正则化的基本方法。
如果我们有非常多的特征,而且我们不知道要惩罚哪些特征,就对所有的特征进行惩罚,这样就得到一个极为简单的能防止过拟合问题的假设 ,其中①λ是正则化参数(λ过大导致惩罚加重,参数越接近0) ②我们一般不对θ0进行惩罚,避免损失函数依赖初始化参数的选择
将正则化应用到线性回归中
对于线性回归的求解,我们之前推导了两种学习算法:一种基于梯度下降,一种基于正规方程。如果我们用梯度下降法让损失函数最小化,因为我们么有对θ0进行正则化,所以梯度下降算法分成2种情况: ,j=1,2,…,n,可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令值减少了一个额外的值。
利用正规方程来求解正则化线性回归模型 $θ=(X^TX+λA)^{-1}X^Ty$,其中A是(n+1)×(n+1)对角线矩阵,对角线上的元素是0,1,1,…,1
将正则化应用到逻辑回归中
给代价函数增加一个正则化的表达式,得到代价函数
梯度下降算法为:,,j=1,2,…,n
梯度下降算法看上去和线性回归一样,但是h的公式不同,所以实际上与线性回归还是不同的。