1、神经网络的概念
非线性假设
我们之前学的,无论是线性回归还是逻辑回归都有一个缺点:当特征太多时,计算的负荷会非常大。比如正则化那一节课的练习题,用x1和x2的多项式进行预测能帮我们建立更好的分类模型,但如果特征非常多,比如用100个变量构造一个非线性的多项式模型,结果将是数量非常惊人的特征组合,这对于一般的逻辑回归来说需要计算的特征太多了。
神经元与神经网络
神经网络最初产生的目的是制造能模拟大脑的机器,它逐渐兴起于二十世纪八九十年代,应用得非常广泛。但由于各种原因,在90年代的后期应用减少了。但最近神经网络又东山再起了,其中一个原因是神经网络的计算量偏大,而近些年计算机的运行速度变快,可以真正运行起大规模的神经网络。
为了构建神经网络模型,我们需要首先思考大脑中的神经网络是怎样的?每一个神经元都可以被认为是一个处理单元/神经核,它含有许多输入/树突,并且有一个输出/轴突。大量神经元相互连接并微弱的电流进行交流形成神经网络,神经元如果想传递一个消息,就会就通过它的轴突,发送一段微弱电流给其它神经元。
一个神经元可能接收信息做一些计算,也可能将自己的信息传递给其它神经元,这就是所有人类思考的模型。而神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型,这些神经元根据本身的模型提供一个输出,或者采纳一些特征作为输出。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量,下图是一个3层的神经网络:
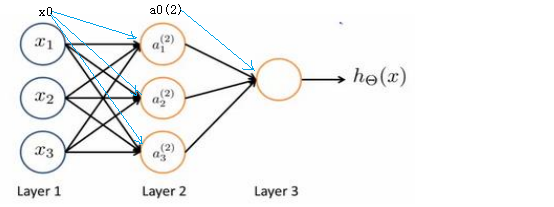
[说明]①第一层(输入层):x1、x2、x3是输入单元,我们将原始数据输入给它们
②隐藏层:a1、a2、a3是中间单元,负责将数据进行处理,再呈递到下一层
③输出层:输出单元负责计算h(x)
我们为每一层都增加一个偏差单元x0、a0
引入一些标记法来帮助描述模型:$a_i^{(j)}$:第j层,第i个激活单元(偏差的i=0);$θ^{(j)}$:从第j层映射到第j+1层的权重矩阵,行数是第j+1层的激活单元的数量,列数是第j层激活单元的数量+1
前向传播算法(Forward Propagation)
(1)针对一个训练实例所进行的计算
对于上图所示的模型,激活单元表示为:,,
输出表示为:
每一个a都是由上一层所有的x和每一个x和a所对应的θ决定的,可以把a看成更高级别的特征,也就是x的进化体,而且远比x次方厉害。把这样从左到右的算法称为前向转播算法。把x、θ、a分别用矩阵表示,可以得到θ·X=a,对于上面的神经网络的例子,计算过程:
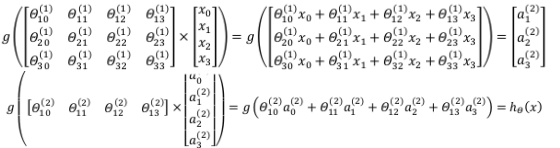
令$z^{(2)}=θ^{(1)}x$,则$a^{(2)}=g(z^{(2)})$,计算出a后再添加$a_0^{(2)}=1$;令$z^{(3)}=θ^{(2)}a^{(2)}$,则最终得出输出值$h_θ(x)=a^{(3)}=g(z^{(3)})$
(2)将整个训练集都喂给神经网络
我们需要将训练集特征矩阵X进行转置,使得同一个实例的特征都在同一列里,即$z^{(2)}=θ^{(1)}X^T$,$a^{(2)}=g(z^{(2)})$
多类分类
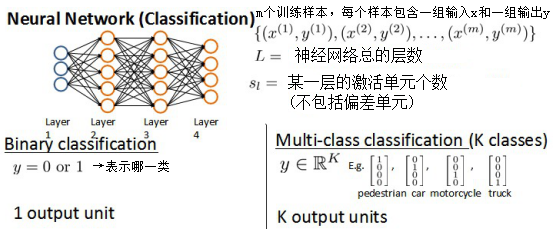
不止有两种分类时,比如训练一个神经网络用来识别路人、汽车、摩托车和卡车,则输出层应该有4个激活单元用来表示4类,即每个数据在输出层都会出现$(a,b,c,d)^T$,而且abcd中只有一个是1,表示当前类,其他都是0
练习
2、神经网络的学习
损失函数
先引入一些便于稍后讨论的新标记方法,再列出逻辑回归和神经网络的损失函数

反向传播算法
之前我们在计算神经网络预测结果时,用的是一种正向传播算法,即从第一层开始正向一层一层进行计算,直到最后一层的h。现在为了计算损失函数对每一层参数的的偏导数,需要一种反向传播算法,即先计算最后一层的误差(误差是激活单元的预测a与实际值y的差别,用δ表示),再一层一层反向求出各层的误差,直到倒数第二层。

梯度检验
当我们对一个较为复杂的模型(比如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,即虽然代价看上去在不断减小,但最终的结果可能并不是最优解。为了避免这样的问题,我们采取“梯度检验”的方法,它通过估计梯度值,来检验我们计算的导数值是否真的是我们要求的
如何估计?①针对一个参数的改变进行的检验:对于某个特定的θ,在损失函数沿着切线方向上选择2个点(θ-ε和θ+ε,ε非常小,一般为0.001),计算[J(θ+ε)-J(θ-ε)]/2ε就是损失函数在θ处的梯度;②当θ是一个向量时,
最后还需要对通过反向传播方法计算出的偏导数进行检验:将计算出的偏导数存储在矩阵$D_{ij}^{(i)}$中,检验时要将矩阵展开为向量;同时也将θ矩阵展开为向量,针对每一个θ都计算一个近似的梯度值,将这些值存储在一个近似梯度矩阵中,将这个矩阵与$D_{ij}^{(i)}$进行比较
随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为同一个非0的数,结果也是一样的。
我们通常初始化参数为正负ε之间的随机值,假设我们要随机初始一个尺寸为10×11的参数矩阵,代码如下:1
Theta1 = rand(10, 11) * (2*eps) – eps
总结使用神经网络时的步骤
【网络结构】第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元
注意:①第一层的单元数即我们训练集的特征数量 ②最后一层的单元数是我们训练集的结果的类的数量 ③如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好 ④我们真正要决定的是隐藏层的层数和每个中间层的单元数。
【训练神经网络】①参数的随机初始化 ②利用正向传播方法计算所有的$h_θ(x) ③编写计算代价函数J的代码 ④利用反向传播方法计算所有偏导数 ⑤利用数值检验方法检验这些偏导数 ⑥使用优化算法来最小化代价函数