1、聚类
无监督学习简介
监督学习:训练数据都带有标签,目标是根据训练数据拟合一个假设函数,即能够区分正样本和负样本的决策边界。非监督学习:训练数据没有附带任何标签,将一系列无标签的训练数据输入到算法中,需要算法帮我们找到这些数据的内在结构。比如下图,数据看起来可以分成2个分开的点集(称为簇),一个能找到这些簇的算法就是聚类算法。
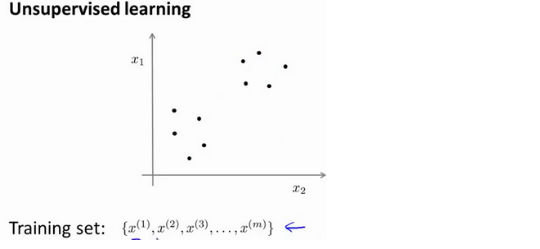
这将是我们介绍的第一个非监督学习算法。当然,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
聚类算法的一些应用:①市场分割:也许你在数据库中存储了许多客户的信息,而你希望将他们分成不同的客户群,这样你可以对不同类型的客户分别销售产品或者分别提供更适合的服务;②社交网络分析:比如你经常跟哪些人联系,而这些人又经常给哪些人发邮件,由此找到关系密切的人群。因此,这可能需要另一个聚类算法,你希望用它发现社交网络中关系密切的朋友;③还可以用聚类算法了解星系的形成
K-均值算法
K-Means是最普及的聚类算法,它接受一个未标记的数据集,然后将数据聚类成不同的组。它是一个迭代算法,假设我们想要将数据聚类成n个组,方法是:①先选择K个随机的点(聚类中心) ②对于数据集中的每一个数据,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类 ③计算每一组的平均值,将该组所关联的中心点移动到平均值的位置 ④重复步骤2-4直至中心点不再变化。K均值的伪代码如下[μ(1)、μ(2)、…、μ(k)表示聚类中心,c(1)、c(2)、…、c(m)表示与样本最近的聚类中心的索引]:1
2
3
4
5
6
7随机初始化μk
Repeat {
for i = 1 to m
c(i) = 距离样本x(i)最近的聚类中心的索引 #归类
for k = 1 to K
μk := 属于的簇k所有样本的平均值 #聚类中心的移动
}
优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,所以损失函数为 ,其中$μ_c^{(i)}$代表与$x^{(i)}$最近的聚类中心点。优化目标就是找出使损失函数最小的$c^{(1)}$,$c^{(2)}$,…,$c^{(m)}$和$μ^1$,$μ^2$,…,$μ^k$
回顾刚才的K-均值迭代算法,第一个循环是用于减小$c^{(i)}$引起的损失,第二个循环则是用于减小$μ^i$引起的损失。迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
随机初始化
在运行K-均值算法之前,我们要先随机初始化所有的聚类中心点,如何操作?①先选择K<m,即聚类中心点的个数要小于所有训练集实例的数量;②随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等。
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择损失函数最小的结果。这种方法在K较小的时候(2~10)还是可行的,但是如果K较大,这么做也可能不会有明显地改善。
选择聚类数K
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。当人们在讨论选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”:改变K值(从1开始),画出损失函数随K值的变化曲线,选择使损失函数值最小的那个K值。因为曲线的形状像人的肘部,所以称为肘部法则。比如开始下降地很快,到K=3之后就下降地很慢了,我们就选K=3
聚类参考资料
(1)相似度/距离计算方法总结
①闵可夫斯基距离Minkowski(p=2时是欧式距离):
②杰卡德相似系数(Jaccard):
③余弦相似度(cosine similarity):n维向量x和y的夹角记做θ,根据余弦定理,其余弦值是
④Pearson皮尔逊相关系数:
Pearson相关系数即将x、y坐标向量各自平移到原点后的夹角余弦
(2)聚类的衡量指标
①均一性p:类似于精确率,一个簇中只包含一个类别的样本,则满足均一性。其实也可以认为就是正确率(每个聚簇中正确分类的样本数占该聚簇总样本数的比例和)
②完整性r:类似于召回率,同类别样本被归类到相同簇中,则满足完整性(每个聚簇中正确分类的样本数占该类型的总样本数比例的和)
③V-measure:均一性和完整性的加权平均
④样本i的轮廓系数s(i):簇内不相似度→计算样本到同簇其它样本的平均距离为a(i),应尽可能小;簇间不相似度→计算样本i到其它簇Cj的所有样本的平均距离$b_{ij}$,应尽可能大;轮廓系数s(i)值越接近1表示样本i聚类越合理,越接近-1,表示样本i应该分类到另外的簇中,近似为0,表示样本i应该在边界上,所有样本的s(i)的均值被成为聚类结果的轮廓系数。
2、降维
降维的动机
(1)数据压缩
介绍第2种类型的无监督学习问题,称为降维。有几个不同的的原因使你可能想要做降维,一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快我们的学习算法。
什么是降维?比如①将数据从2维降至1维:用2种不同的仪器测量,我们希望将测量的结果作为机器学习的特征,问题是两种仪器对同一个东西测量的结果不完全相等(由于误差、精度等原因),而将两者都作为特征有些重复,所以希望将这个2维数据降至1维,可以将所有2维数据投影到一条直线上;②将数据从3维降至2维:将3维向量投射到一个2维的平面上,强迫使得所有的数据都在同一个平面上;③这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,比如将1000维的特征降至100维
(2)数据可视化
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。这样做的问题在于,降维的算法只负责减少维数,新特征的意义就必须由我们自己去发现了
主成分分析问题
主成分分析(PCA)是最常见的降维算法。在PCA中,我们要做的是找到一个方向向量(一个经过原点的向量),当把所有的数据都投射到该向量上时,我们希望平均均方投射误差能尽可能小,投射误差是从特征向量向该方向向量作垂线的长度(线性回归的误差是垂直于x轴的投影,PCA的误差是垂直于方向向量的投影)。
PCA的目的是为了将n为数据降至k维,要找到向量$u^{(1)}$,$u^{(2)}$,…,$u^{(k)}$使得总的投射误差最小。对新求出的主元向量的重要性进行排序,根据需要提取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或对数据进行压缩的效果,同时最大限度地保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。但一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
主成分分析算法
第一步:均值归一化。我们需要计算出所有特征的均值,然后令$x_j=x_j-μ_j$。如果特征是在不同的数量级上,我们还需要将其除以标准差说σ²
第二步:计算协方差矩阵Σ:
第三步:计算协方差矩阵Σ的特征向量,可以用奇异值分解来求解。[U,S,V]=svd(Sigma),对于一个n×n矩阵,U是一个具有与数据之间最小投射误差的方向向量构成的矩阵,如果我们希望将数据从n维降至k维,我们只需要从U中选取前k个向量,获得一个n×k的矩阵,然后通过如下计算获得要求的新特征向量$z^{(i)}=U_{reduce}^T*x^{(i)}$,其中x是n×1,所以结果是k×1
选择主成分的数量k
PCA希望在平均均方误差、训练集方差的比例尽可能小的情况下,选择尽可能小的k值。如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令k=1,然后进行主要成分分析,获得$U_{reduce}$和z,然后计算比例是否小于1%。如果不是的话再令k=2,如此类推,直到找到可以使得比例小于1%的最小k值(原因是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择k,当我们在调用奇异值分解函数时,我们获得三个参数 [U,S,V] = svd(sigma),其中S是一个n×n的对角矩阵,可以用这个矩阵来计算平均均方误差与训练集方差的比例: / = / 1%,也就是
在压缩过数据后,我们可以采用如下方法来近似得获得原有特征:$x_{approx}^{(i)}=U_{reduce}z^{(i)}$
PCA的应用建议
我们针对一张100×100像素(即共有10000个特征)的图片进行计算机视觉的机器学习:①第一步是运用主要成分分析将数据压缩至1000个特征 ②然后对训练集运行学习算法 ③在预测时,采用之前学习而来的$U_{reduce}$将输入的特征x转换成特征向量z,然后再进行预测。注意:如果我们有交叉验证集合测试集,也采用对训练集学习而来的$U_{reduce}$
错误使用PCA的两种情况:①将PCA用于减少过拟合(减少了特征的数量),这样做很不好,不如用正则化处理,因为PCA只是近似地丢弃掉一些特征,并不考虑任何与结果变量有关的信息,所以可能会丢失很重要的特征。而正则化会考虑到结果变量,不会丢掉重要的数据;②默认地将主PCA作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用PCA。
练习
①构建k-means聚类算法并将其用于图像压缩 ②构建PCA算法并将其用于图像压缩和可视化
非监督学习
3、异常检测
异常检测的动机
异常检测是机器学习算法的一个常见应用,这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
什么是异常检测?给定数据集,假设数据集是正常的,我们希望知道新的数据是不是异常的,即这个测试数据不属于该组数据的几率如何。我们所构建的模型应该能根据该测试数据的位置告诉我们其属于一组数据的可能性。
应用:主要用来识别欺骗。例如在线采集而来的有关用户的数据,一个特征向量中可能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户。
用高斯分布开发异常检测算法
如果我们认为变量x服从高斯分布,则可以用数据预测总体的μ和σ²,注意机器学习中对于方差我们通常只除以m,而非统计学中的m-1,在实际使用中,到底除以哪个其实区别很小,只要你有一个还算大的训练集。这两个版本的公式在理论特性和数学特性上稍有不同,但是在实际使用中,他们的区别甚小,几乎可以忽略不计。
对于给定的数据集,我要针对每一个特征计算μ和σ²的估计值:,,获得了平均值和方差的估计值后,给定一个新的训练实例,根据模型计算p(x):,当p(x)<ε时为异常
开发和评估一个异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量y的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。比如我们有10000台正常引擎的数据,有20台异常引擎的数据。
我们这样分配数据:6000台正常引擎的数据作为训练集,2000台正常引擎和10台异常引擎的数据作为交叉检验集,2000台正常引擎和10台异常引擎的数据作为测试集。
具体的评价方法如下:①根据测试集数据,我们估计特征的平均值和方差并构建p(x)函数;②对交叉检验集,我们尝试使用不同的ε值作为阀值,并预测数据是否异常,根据F1值或者查准率与查全率的比例来选择ε;③选出ε后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比。
异常检测与监督学习的对比
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对比有助于选择采用监督学习还是异常检测:
【异常检测】①非常少量的正向类(异常数据y=1), 大量的负向类(y=0)②许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法 ③未来遇到的异常可能与已掌握的异常、非常的不同 ④例子:欺诈行为检测,生产(例如飞机引擎)检测数据中心的计算机运行状况
【监督学习】①同时有大量的正向类和负向类 ②有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似 ③例子:邮件过滤器 天气预报。
选择特征
对于异常检测算法,特征是至关重要的,那么如何选择特征?异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,即对特征进行一些小小的转换,例如使用对数函数:x=log(x+c),其中c是非负常数,或者$x=x^c$,c是0~1之间的一个分数。
误差分析:一个常见的问题是一些异常的数据可能也会有较高的p(x)值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测