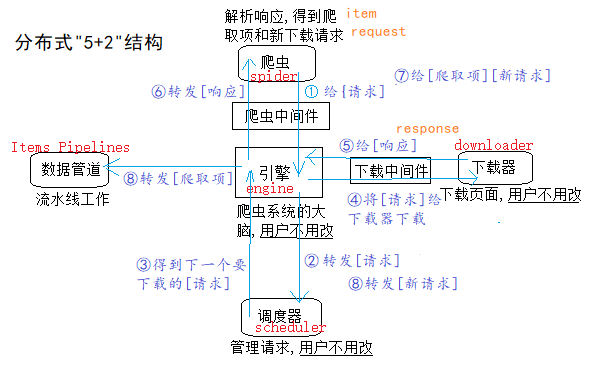
一、Scrapy框架结构
二、构建scrapy爬虫项目的基本步骤
步骤:①创建项目
②定义保存数据的容器Item
③编写提取数据的爬虫Spider
④构建处理数据的流水线Pipeline
1、创建项目
创建项目之前需要做的准备工作:
①明确项目需求:在哪个网站的哪些数据
②页面分析:从大框架找小框架。比如提取图书馆网页的书籍信息(书籍列表页面→书籍框架→名称/价格/作者等)1
2
3
4
5
6
7
8# ①书籍列表页面→书籍框架:使用scrapy shell命令下载页面,然后用view函数在浏览器中查看下载后的页面
#运行之后,网页会被下载到response对象中,可以用来调试XPath或CSS→得到正确的表达式
>>scrapy shell http://books.toscrape.com/
>>view(response)
# 查看发现所有的书籍框架都在<article class="product_pod">..</article>中
# ②书籍框架→名称/价格/作者等:可以直接从已下载的页面中找到这些数据
创建项目:
在指定文件夹中新建一个爬虫项目1
2
3
4
5>>cd 目标文件夹
>>scrapy startproject 项目目录名
>>cd 项目目录名
>>scrapy genspider books books.toscrape.com
#创建一个新的spider。其中books是spider的唯一标识符(每个爬虫项目可以有多个spider文件),最后是爬虫起点
新建完成后,会得到下列文件结构:

【补充】为什么每个文件目录下都有_pycache_?这涉及到Python的运行机制,也就是它不需要编译成二进制代码,而是由解释器直接从源码运行程序。解释器的具体工作是:①加载模块 ②将源码编译为PyCodeObject对象(即字节码),写入内存中 ③从内存中读取并执行字节码,结束后将字节码写回硬盘当中,也就是复制到.pyc或.pyo文件中,以保存当前目录下所有脚本的字节码文件,之后如果想再次执行该脚本,先检查本地是否有字节码文件、该字节码文件的修改时间是否与其脚本一致,如果都满足就直接执行,否则重复上述步骤。
2、定义保存数据的容器Item
Item是保存爬取到的数据的容器。比如爬取某图书网站的书籍信息,对于每本书可提取书名、价格等,如果用字典维护这些零散的信息字段,会有以下缺点:①无法一目了然地了解数据中包含哪些字段,影响代码可读性 ②缺乏对字段名字的检测,容易因程序员的笔误而出错 ③不便于携带元数据(传递给其他组件的信息)。用Item可以解决上述问题。
定义Item
这里Scrapy提供了两个类:Item基类(自定义数据类的基类)和Field类(用来描述数据类包含哪些字段)。自定义一个数据类,只需继承Item基类,并创建一系列Field对象的类属性即可。1
2
3
4
5
6# 书籍信息包含两个字段:书名name、书价price
# 在items.py中实现BookItem类
from scrapy import Item,Field
class BookItem(Item):
name = Field()
price = Field()
【补充】有时我们可能要对已有的自定义数据类进行拓展,比如项目中又添加了一个新的Spider,负责在其他图书网站爬取国外书籍,书籍信息比之前多了一个译者字段。此时可以继承BookItem,定义一个ForeignBookItem类,在其中添加一个译者字段1
2class ForeignBookItem(BookItem):
translator = Field()
创建BookItem对象
Item支持字典接口,因此BookItem在使用上和Python字典类似(实际上Field是Python字典的子类)1
2
3
4
5
6#方法一:
book1 = BookItem(name='Needful Things',price=45.0)
#方法二:
book2 = BookItem()
book2['name'] = 'Life of Pi'
book2['price'] = 32.5
对字段进行赋值
BookItem内部会检测字段名,如果给一个没有定义的字段赋值,会抛出异常(防止因用户粗心而导致错误)1
2
3book = BookItem()
book['name'] = 'Memoris of a Geisha'
book['prize'] = 43.0 #粗心,把price拼写成立prize,抛出异常
访问BookItem对象中的字段
1 | book = BookItem(name='Needful Things',price=45.0) |
使用元数据(Field)给其他组件传递信息
【例1】给其他组件传递额外的信息1
2
3class ExampleItem(Item):
x = Field(a='hello',b=[1,2,3]) x有两个元数据,a是个字符串,b是个列表
y = Field(a=lambda x:x ** 2) y有一个元数据,a是个函数
访问ExampleItem对象的fields属性,将得到一个字典(包含所有Field对象)1
2
3
4
5
6
7
8
9
10
11e = ExampleItem(x=100,y=200)
e.fields #返回{'x':{'a':'hello','b':[1,2,3]}, 'y':{'a':<function__main__.ExampleItem.<lambda>>}}
type(e.fields['x']) #返回scrapy.item.Field
type(e.fields['y']) #返回scrapy.item.Field
issubclass(Field,dict) #返回True
field_x=e.fields['x'] #注意不要混淆e.fields['x']和e['x']
field_x #返回{'a':'hello','b':[1,2,3]}
field_x['a'] #返回'hello'
field_y = e.fields['y']
field_y #返回{'a':<function__main__.ExampleItem.<lambda>>}
field_y.get('a',lambda x:x) #返回<function__main__.ExampleItem.<lambda>>
【例2】爬取的信息有时是一个字符串列表,比如book[‘authors’]=[‘A’,’B’,’C’],当写入csv文件时应该将所有字符串合并为一个字符串(串行化),我们可以通过authors字段的元数据,告诉其他组件如何对authors字段的串行化1
2class BookItem(Item):
authors = Field(serializer = lambda x:'|'.join(x))
其中,元数据的键serializer是CsvItemExporter规定好的,它会用该键获取一个串行化函数,并用这个函数将authors字段串行化成一个字符串。