对“数据分析师职位招聘分析”所收集的数据进行清洗
一、了解数据
部分数据如下所示:
考虑到英文比汉字更适合编程环境,所以数据源的字段名都是英文,各个字段的含义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14city 城市
district 市辖区
companyShortName 公司简称
companySize 公司规模
companyId 公司ID
financeStage 融资阶段
industryField 公司所属领域
positionName 职位名称
firstType 职位所属一级类目
secondType 职位所属二级类目
thirdType 职位所属三级类目
education 学历要求
workYear 工作年限要求
salary 薪水
二、清洗数据
首先新建一个sheet,将原始数据复制过来,在新建的sheet中进行数据清洗操作。
1、缺失值处理
通过选取该字段,在屏幕的左下角查看计数来查看每个字段是否存在缺失值。结果发现district(缺失20个)、companySize(缺失1个)、financeStage(缺失1个)、industryField(缺失1个),
(1)定位缺失值的方法
方法1:按ctrl+G打开定位对话框,选择”空值”并点击”确定”
方法2:用筛选功能,点击下拉箭头,只选择”空白”
(2)填充缺失值
①这里我通过搜索公司信息,手动填充对应的district信息;
②其它缺失信息都属于一家公司的分公司,忽略
2、不一致数据的处理
通过筛选查看数据,发现以下几种数据不一致的情况:
(1)公司领域字段:”O2O ,生活服务”与”O2O,生活服务”是一类,但被归为两种不同的类,只是因为一个空格的差别;因为有二级类目所以该字段划分了很多类别,这里我只保留一级类别。
方法:在该列后面插入一列(否则分列后会覆盖右边字段的数据),”数据”→”分列”→选择分隔符号:空格、逗号、顿号
(2)职位类目的三个字段:将”/“改为”|”
3、删除重复项
重复项是指在每个字段(或选定字段)都有相同的内容。删除重复项的方法如下
方法一:”数据”→”删除重复项”→选择重复数据所在的列→点击确定,就会自动得到删除重复项之后的数据,删除的空白行也会自动由下方数据填补
方法二:”筛选”→”高级筛选”→勾上”选择不重复的记录”
这里采用方法一,找到513条重复项,删除后将保留3526条唯一项。
4、文本转为数值类型
薪水用”几K到几k”的形式表示,是一个文本字符串,我需要将它的数值(最高薪水、最低薪水)提取出来,用来计算平均工资,用这个平均数作为该岗位的薪水。将salary拆成最高薪水和最低薪水的方法:
方法一:直接分列。”数据”→”分列”,以”-“为分割符,得到两列数据,再利用替换功能删除k这个字符串得到结果
方法二:用公式。先用SEARCH(“k”,N2)查找第一个k出现的位置①,LEFT(N2,位置①-1)就得到最低薪水值;用SEARCH(“-“,N2)查找”-“的位置②,最高薪水MID(N2,位置②+1,LEN(N2)-位置②-1)
最终的公式是:
最低薪水 = LEFT(N2,SEARCH(“k”,N2)-1)
最高薪水 = MID(N2,SEARCH(“-“,N2)+1,LEN(N2)-SEARCH(“-“,N2)-1)
最终结果如下图所示: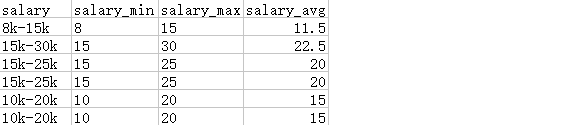
用到的函数如下:1
2
3
4
5
6
7
8
9SEARCH(查找的文本,文本所在的单元格,从第几个字符开始找默认是1)
用来对原始数据中某个字符串进行定位,以确定其位置。
SEARCH函数进行定位时,总是从指定位置开始,返回找到的第一个匹配字符串的位置。
FIND函数用法相同,只是FIND对大小写敏感,SEARCH忽略大小写
LEFT(单元格,从左开始截取几个字符)
用来对单元格内容进行截取。从左边第一个字符开始截取,截取指定的长度
MID(单元格,从第几个字符开始提取,提取几个字符)